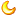|
|
<
导读 作者:沃趣-罗小波 概要:原文包罗PXC、MGR、MGC集群之新建、备份、恢复操作步骤详解,因篇幅较长,本文仅节取MGR部分内容。 若想了解完整文章,可至文末获取
对于PXC、MGC、MGR三种MySQL的集群复制架构技能,其实在更早之前,我做过一个视频版的 "PXC、MGC & MGR 原理与实践对比" 系列课程,但有部分同学觉得里边的内容缺少详细操作步骤。所以,今天我就将PXC、MGR、MGC集群之新建、备份、恢复操作的详细步骤整理出来分享给各人,希望能资助各人更好地玩耍PXC、MGC、MGR
一、原文目录
1、PXC1.1. 集群初始化1.1.1. 第一个节点(init)1.1.2. 第二个节点(sst)1.1.3. 第三个节点(backup recovery)1.2. 集群新增节点1.2.1. 使用备份集恢复1.2.2. 全量SST加入集群1.3. 单节点crash的恢复1.4. 多数节点crash的恢复1.4.1. crash节点数据未丢失且可以原地恢复1.4.2. crash节点数据丢失1.5. 整个集群crash的恢复1.5.1. 使用备份恢复1.5.2. 使用crash节点的datadir数据卷进行恢复2、MGC3、MGR 3.1. 集群初始化 3.1.1. 第一个节点(init)3.1.2. 第二个节点(全量复制)3.1.3. 第三个节点(backup recovery) 3.2. 集群新增节点3.2.1. 使用备份集恢复3.2.2. 全量复制加入集群 3.3. 单节点crash的恢复 3.4. 多数节点crash的恢复3.4.1. crash节点数据未丢失且可以原地恢复3.4.2. crash节点数据丢失 3.5. 整个集群crash的恢复3.5.1. 使用备份恢复3.5.2. 使用crash节点的datadir数据卷进行恢复
二、背景说明 服务器环境
- kvm ip:10.10.30.162/163/164
- CPU:8 vcpus
- 内存:16G
- 磁盘:data 100G flash卡,binlog 100G flash卡
数据库版本
- MGC:MariaDB 10.2.12
- MGR:MySQL 5.7.21
- PXC:Percona-Xtradb-Cluster 5.7.21
sysbench版本
- sysbench 1.0.7
- 造数量:8个表,单表500W数据量
PS
- PXC:为Percona Xtradb Cluster的缩写
- MGR:为MySQL Group Replication的缩写
- MGC:为MariaDB Galera Cluster的缩写
三、原文节选:
3、MGR 3.1. 集群初始化
3.1.1. 第一个节点(init)
- server_id=3306162
- sync_binlog=10000
- innodb_flush_log_at_trx_commit = 2
- binlog-checksum=NONE
- innodb_support_xa=OFF
- auto_increment_increment=3
- auto_increment_offset=1
- binlog_row_image=full
- transaction-write-set-extraction=XXHASH64
- loose-group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
- loose-group_replication_single_primary_mode=OFF
- loose-group_replication_enforce_update_everywhere_checks=ON
- loose-group_replication_start_on_boot=on
- loose-group_replication_ip_whitelist='0.0.0.0/0'
- loose-group_replication_local_address='10.10.30.162:24901'
- loose-group_replication_group_seeds='10.10.30.162:24901,10.10.30.163:24901,10.10.30.164:24901'
- loose-group_replication_bootstrap_group=OFF
- report_host='node1'
- 配置hosts剖析记录(有DNS即系服务的环境无需配置)
- [root@localhost ~]# cat /etc/hosts
- ......
- 10.10.30.162 node1 mysql1
- 10.10.30.163 node2 mysql2
- 10.10.30.164 node3 mysql3
- # 存活节点停止组复制插件
- root@localhost : (none) 11:51:15> stop group_replication;
- Query OK, 0 rows affected (1 min 27.08 sec)
- root@localhost : sbtest 11:52:10> set global read_only=1;set global super_read_only=1;
- Query OK, 0 rows affected (0.00 sec)
- Query OK, 0 rows affected (0.00 sec)
- # 可以看到未提交事务被回滚
- root@localhost : sbtest 11:29:02> delete from sbtest1 where id=1;
- ......
- ERROR 3101 (HY000): Plugin instructed the server to rollback the current transaction.
- SET SQL_LOG_BIN=0;
- CREATE USER 'xtrabackup'@'localhost' IDENTIFIED BY 'xtrabackuppass';
- GRANT SELECT, LOCK TABLES, SUPER, REPLICATION CLIENT, REPLICATION SLAVE, RELOAD, CREATE TABLESPACE, PROCESS ON *.* TO 'xtrabackup'@'localhost';
- grant DROP, CREATE, INSERT on mysql.ibbackup_binlog_marker to 'xtrabackup'@'localhost';
- CREATE USER repl@'%' IDENTIFIED BY 'password';
- GRANT REPLICATION SLAVE ON *.* TO repl@'%' ;
- SET SQL_LOG_BIN=1;
- FLUSH PRIVILEGES;
- INSTALL PLUGIN group_replication SONAME 'group_replication.so';
- CHANGE MASTER TO MASTER_USER='repl', MASTER_PASSWORD='password' FOR CHANNEL 'group_replication_recovery';
- FLUSH PRIVILEGES ;
- set global group_replication_bootstrap_group=ON;
- start group_replication;
- set global group_replication_bootstrap_group=OFF;
- #查看状态是否为online
- root@localhost : (none) 03:39:20> SELECT * FROM performance_schema.replication_group_members;
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | group_replication_applier | 2d623f55-2111-11e8-9cc3-0025905b06da | node1 | 3306 | ONLINE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- 1 row in set (0.00 sec)
PS:MGR更多的配置参数参考模板链接如下:
https://github.com/Percona-Lab/percona-docker/blob/master/pgr-57/node.cnf
3.1.2. 第二个节点(全量复制)
- server_id=3306163
- sync_binlog=10000
- innodb_flush_log_at_trx_commit = 2
- innodb_support_xa=OFF
- binlog-checksum=NONE
- auto_increment_increment=3
- auto_increment_offset=2
- binlog_row_image=full
- transaction-write-set-extraction=XXHASH64
- loose-group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
- loose-group_replication_single_primary_mode=OFF
- loose-group_replication_enforce_update_everywhere_checks=ON
- loose-group_replication_start_on_boot=on
- loose-group_replication_ip_whitelist='0.0.0.0/0'
- loose-group_replication_local_address='10.10.30.163:24901'
- loose-group_replication_group_seeds='10.10.30.162:24901,10.10.30.163:24901,10.10.30.164:24901'
- loose-group_replication_bootstrap_group=OFF
- report_host='node2'
- 配置hosts剖析记录(有DNS即系服务的环境无需配置)
- [root@localhost ~]# cat /etc/hosts
- ......
- 10.10.30.162 node1 mysql1
- 10.10.30.163 node2 mysql2
- 10.10.30.164 node3 mysql3
- # 存活节点停止组复制插件
- root@localhost : (none) 11:51:15> stop group_replication;
- Query OK, 0 rows affected (1 min 27.08 sec)
- root@localhost : sbtest 11:52:10> set global read_only=1;set global super_read_only=1;
- Query OK, 0 rows affected (0.00 sec)
- Query OK, 0 rows affected (0.00 sec)
- # 可以看到未提交事务被回滚
- root@localhost : sbtest 11:29:02> delete from sbtest1 where id=1;
- ......
- ERROR 3101 (HY000): Plugin instructed the server to rollback the current transaction.
- SET SQL_LOG_BIN=0;
- CREATE USER 'xtrabackup'@'localhost' IDENTIFIED BY 'xtrabackuppass';
- GRANT SELECT, LOCK TABLES, SUPER, REPLICATION CLIENT, REPLICATION SLAVE, RELOAD, CREATE TABLESPACE, PROCESS ON *.* TO 'xtrabackup'@'localhost';
- grant DROP, CREATE, INSERT on mysql.ibbackup_binlog_marker to 'xtrabackup'@'localhost';
- CREATE USER repl@'%' IDENTIFIED BY 'password';
- GRANT REPLICATION SLAVE ON *.* TO repl@'%' ;
- SET SQL_LOG_BIN=1;
- FLUSH PRIVILEGES;
- INSTALL PLUGIN group_replication SONAME 'group_replication.so';
- CHANGE MASTER TO MASTER_USER='repl', MASTER_PASSWORD='password' FOR CHANNEL 'group_replication_recovery';
- FLUSH PRIVILEGES ;
- reset master;
- start group_replication;
- #查看状态是否为online
- root@localhost : (none) 03:45:24> SELECT * FROM performance_schema.replication_group_members;
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | group_replication_applier | 2d623f55-2111-11e8-9cc3-0025905b06da | node1 | 3306 | ONLINE |
- | group_replication_applier | f64f9fb6-2da4-11e8-96bd-525400c33752 | node2 | 3306 | ONLINE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- 2 rows in set (0.00 sec)
- root@localhost : (none) 06:48:32> select * from performance_schema.replication_group_member_stats where MEMBER_ID=@@server_uuid\G;
- *************************** 1. row ***************************
- CHANNEL_NAME: group_replication_applier
- VIEW_ID: 15218000786938271:11
- MEMBER_ID: 0a1e8349-2e87-11e8-8c9f-525400bdd1f2
- COUNT_TRANSACTIONS_IN_QUEUE: 287640 # 该字段显示当前接收到的relay log与当前应用到的relay log之间的事务差异
- COUNT_TRANSACTIONS_CHECKED: 0
- COUNT_CONFLICTS_DETECTED: 0
- COUNT_TRANSACTIONS_ROWS_VALIDATING: 0
- TRANSACTIONS_COMMITTED_ALL_MEMBERS: 2d623f55-2111-11e8-9cc3-0025905b06da:1-2,
- aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:1-13779 # 该字段显示当前节点应用到的日志对应的GTID
- LAST_CONFLICT_FREE_TRANSACTION:
- 1 row in set (0.02 sec)
- PS:该方式必须保证集群中已有节点的binlog未执行过清理,一旦有清理,新加节点无法通过全量binlog复制来加入集群
3.1.3. 第三个节点(backup recovery)
- 首先,使用sysbench制造一些测试数据,然后,使用sysbench持续对集群发起oltp压力
- # 创建数据库
- root@localhost : (none) 01:44:33> create database sbtest;
- Query OK, 1 row affected (0.00 sec)
- # 使用sysbench造数
- sysbench --db-driver=mysql --time=180 --threads=8 --report-interval=1 --mysql-socket=/home/mysql/data/mysqldata1/sock/mysql.sock --mysql-port=3306 --mysql-user=qbench --mysql-password=qbench --mysql-db=sbtest --tables=8 --table-size=5000000 oltp_read_write --db-ps-mode=disable prepare
- # 使用sysbench加压
- sysbench --db-driver=mysql --time=99999 --threads=8 --report-interval=1 --mysql-socket=/home/mysql/data/mysqldata1/sock/mysql.sock --mysql-port=3306 --mysql-user=qbench --mysql-password=qbench --mysql-db=sbtest --tables=8 --table-size=5000000 oltp_read_write --db-ps-mode=disable run
- server_id=3306164
- sync_binlog=10000
- innodb_flush_log_at_trx_commit = 2
- innodb_support_xa=OFF
- binlog-checksum=NONE
- auto_increment_increment=3
- auto_increment_offset=3
- binlog_row_image=full
- transaction-write-set-extraction=XXHASH64
- loose-group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
- loose-group_replication_single_primary_mode=OFF
- loose-group_replication_enforce_update_everywhere_checks=ON
- loose-group_replication_start_on_boot=on
- loose-group_replication_ip_whitelist='0.0.0.0/0'
- loose-group_replication_local_address='10.10.30.164:24901'
- loose-group_replication_group_seeds='10.10.30.162:24901,10.10.30.163:24901,10.10.30.164:24901'
- loose-group_replication_bootstrap_group=OFF
- report_host='node3'
- 配置hosts剖析记录(有DNS即系服务的环境无需配置)
- [root@localhost ~]# cat /etc/hosts
- ......
- 10.10.30.162 node1 mysql1
- 10.10.30.163 node2 mysql2
- 10.10.30.164 node3 mysql3
- 在第二个节点上进行备份,并把备份传输到第三个节点上
- innobackupex --defaults-file=/etc/my.cnf --slave-info \
- --user=xtrabackup --password=xtrabackuppass --no-timestamp \
- --stream=tar ./ | ssh root@10.10.30.164 "cat - > /archive/backup/backup_`date +%Y%m%d`.tar"
- # innobackupex执行apply-log并move-back备份数据到datadir下
- [root@localhost backup]# tar xvf backup_20180322.tar
- [root@localhost backup]# innobackupex --apply-log ./
- [root@localhost backup]# rm -rf /data/mysqldata1/{undo,innodb_ts,innodb_log,mydata,binlog,relaylog,binlog,slowlog,tmpdir}/*
- [root@localhost backup]# innobackupex --defaults-file=/etc/my.cnf --move-back ./
- ......
- chown mysql.mysql /data -R
- mysqld_safe --defaults-file=/etc/my.cnf --loose-group_replication_start_on_boot=off &
- [root@localhost backup]# cat xtrabackup_binlog_info
- mysql-bin.000147 103011527 2d623f55-2111-11e8-9cc3-0025905b06da:1-3,
- aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:1-87512845
- 登录数据库,执行重设gtid,并重新拉起group replication
- root@localhost : (none) 01:38:35> reset master;
- Query OK, 0 rows affected (0.02 sec)
- root@localhost : (none) 01:39:25> set global gtid_purged='2d623f55-2111-11e8-9cc3-0025905b06da:1-3,aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:1-87512845';
- Query OK, 0 rows affected (0.00 sec)
- root@localhost : (none) 01:39:53> set global group_replication_start_on_boot=on;
- Query OK, 0 rows affected (0.00 sec)
- root@localhost : (none) 01:40:59> start group_replication;
- Query OK, 0 rows affected (2.66 sec)
- #查看状态是否为online,
- root@localhost : (none) 11:16:52> SELECT * FROM performance_schema.replication_group_members;
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | group_replication_applier | 2d623f55-2111-11e8-9cc3-0025905b06da | node1 | 3306 | ONLINE |
- | group_replication_applier | 859b114c-2e48-11e8-9eac-525400bdd1f2 | node3 | 3306 | RECOVERING |
- | group_replication_applier | f64f9fb6-2da4-11e8-96bd-525400c33752 | node2 | 3306 | ONLINE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- 3 rows in set (0.00 sec)
- ......
- root@localhost : (none) 01:43:23> select * from performance_schema.replication_group_members;
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | group_replication_applier | 2d623f55-2111-11e8-9cc3-0025905b06da | node1 | 3306 | ONLINE |
- | group_replication_applier | 62392979-2e5c-11e8-a389-525400bdd1f2 | node3 | 3306 | ONLINE |
- | group_replication_applier | f64f9fb6-2da4-11e8-96bd-525400c33752 | node2 | 3306 | ONLINE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- 3 rows in set (0.00 sec)
PS:如果是快照拷贝的数据,需要删除datadir/auto.cnf文件
3.2. 集群新增节点
3.2.1. 使用备份集恢复
PS:
由于在多线程复制下,使用xtrabackup备份读节点高概率会导致发生锁死现象(sysbench 128线程insert操作百分百重现),所以在MGR架构上的备份只能考虑在写节点上备份(备选方案1:在集群上挂一个主从架构的备库,使用xtrabackup的--safe-slave-backup选项在加锁前停止SQL线程来避免锁死现象。备选方案2:假定半夜写压力不高,轮询线程信息,发现备份线程锁请求被锁死时,主动登录数据库kill掉加锁线程并尝试重新备份),锁死现象如下
3.2.2. 全量复制加入集群
- 参考3.1.2小节
- 无新节点全量复制加入集群时的qps曲线图
PS: 全量复制新加节点会触发流控,导致性能陡降,关闭流控性能可恢复到正常状态,但需要所有节点同时关闭才生效 - root@localhost : (none) 06:52:16> set global group_replication_flow_control_mode=DISABLED;
- Query OK, 0 rows affected (0.01 sec)
做一些必要的检查之后,尝试直接以常规方式拉起节点,如果不能正常拉起或者crash节点数据丢失,则通过备份进行恢复(详细步骤参考3.1.3小节)。
3.4. 多数节点crash的恢复
两种方式(针对至少有一个节点的实例可登陆,且集群不可用的情况)
- 如果crash节点能够原地恢复(带着crash之前的数据直接拉起实例),则集群可以正常恢复到可读写状态(即存活节点恢复到>=N/2+1个,且都正确重新加入到集群中)
- 如果所有crash节点数据丢失,则无法重新加入集群,此时如果要恢复集群,需要在存活的节点上停止集群复制插件,使其脱离集群变为可读写状态,然后再恢复其他节点(使用xtrabackup备份存活节点数据做恢复)
3.4.1. crash节点数据未丢失且可以原地恢复
<ul class="list-paddingleft-2">
集群存活节点数 select * from performance_schema.replication_group_members;+---------------------------+--------------------------------------+-------------+-------------+--------------+| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |+---------------------------+--------------------------------------+-------------+-------------+--------------+| group_replication_applier | 0a1e8349-2e87-11e8-8c9f-525400bdd1f2 | node3 | 3306 | ONLINE || group_replication_applier | 2d623f55-2111-11e8-9cc3-0025905b06da | node1 | 3306 | UNREACHABLE || group_replication_applier | 506759a9-2e83-11e8-b454-525400c33752 | node2 | 3306 | UNREACHABLE |+---------------------------+--------------------------------------+-------------+-------------+--------------+3 rows in set (0.00 sec)# 尝试读写操作## 读操作root@localhost : (none) 10:15:10> use sbtestDatabase changedroot@localhost : sbtest 10:15:52> select * from sbtest1 limit 1;+----+---------+----------------------------------------------------------------------+-------------------------------------------------------------+| id | k | c | pad |+----+---------+-----------------------------------------------------------------------+-------------------------------------------------------------+| 1 | 2507307 | 68487932199-96439406143-93774651418-41631865787-96406072701-20604855487-25459966574-28203206787-41238978918-19503783441 | 22195207048-70116052123-74140395089-76317954521-98694025897 |+----+---------+------------------------------------------------------------------------+-------------------------------------------------------------+1 row in set (0.01 sec)## 写操作root@localhost : sbtest 10:25:43> delete from sbtest1 where id=1; # 写操作被阻塞!!不是报错......[/code]
- 另起一个mysql客户端,登录第三个节点实例中停止组复制插件
- [root@localhost ~]# ssh 10.10.30.162 "killall -9 mysqld mysqld_safe 2> /dev/null &";ssh 10.10.30.163 "killall -9 mysqld mysqld_safe &> /dev/null &";
- # 查看集群成员状态
- root@localhost : (none) 10:15:09> select * from performance_schema.replication_group_members;
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | group_replication_applier | 0a1e8349-2e87-11e8-8c9f-525400bdd1f2 | node3 | 3306 | ONLINE |
- | group_replication_applier | 2d623f55-2111-11e8-9cc3-0025905b06da | node1 | 3306 | UNREACHABLE |
- | group_replication_applier | 506759a9-2e83-11e8-b454-525400c33752 | node2 | 3306 | UNREACHABLE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- 3 rows in set (0.00 sec)
- # 尝试读写操作
- ## 读操作
- root@localhost : (none) 10:15:10> use sbtest
- Database changed
- root@localhost : sbtest 10:15:52> select * from sbtest1 limit 1;
- +----+---------+----------------------------------------------------------------------+-------------------------------------------------------------+
- | id | k | c | pad |
- +----+---------+-----------------------------------------------------------------------+-------------------------------------------------------------+
- | 1 | 2507307 | 68487932199-96439406143-93774651418-41631865787-96406072701-20604855487-25459966574-28203206787-41238978918-19503783441 | 22195207048-70116052123-74140395089-76317954521-98694025897 |
- +----+---------+------------------------------------------------------------------------+-------------------------------------------------------------+
- 1 row in set (0.01 sec)
- ## 写操作
- root@localhost : sbtest 10:25:43> delete from sbtest1 where id=1; # 写操作被阻塞!!不是报错
- ......
- # 存活节点停止组复制插件
- root@localhost : (none) 11:51:15> stop group_replication;
- Query OK, 0 rows affected (1 min 27.08 sec)
- root@localhost : sbtest 11:52:10> set global read_only=1;set global super_read_only=1;
- Query OK, 0 rows affected (0.00 sec)
- Query OK, 0 rows affected (0.00 sec)
- # 可以看到未提交事务被回滚
- root@localhost : sbtest 11:29:02> delete from sbtest1 where id=1;
- ......
- ERROR 3101 (HY000): Plugin instructed the server to rollback the current transaction.
- root@localhost : (none) 12:30:20> set global group_replication_bootstrap_group=ON;
- Query OK, 0 rows affected (0.00 sec)
- root@localhost : (none) 12:33:25> start group_replication;
- Query OK, 0 rows affected (2.04 sec)
- root@localhost : (none) 12:33:29> set global group_replication_bootstrap_group=ON;
- Query OK, 0 rows affected (0.00 sec)
- root@localhost : sbtest 12:28:31> set global read_only=0;set global super_read_only=0;
- Query OK, 0 rows affected (0.00 sec)
- Query OK, 0 rows affected (0.00 sec)
3.4.2. crash节点数据丢失
<ul class="list-paddingleft-2">
集群存活节点数 select * from performance_schema.replication_group_members;+---------------------------+--------------------------------------+-------------+-------------+--------------+| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |+---------------------------+--------------------------------------+-------------+-------------+--------------+| group_replication_applier | 0a1e8349-2e87-11e8-8c9f-525400bdd1f2 | node3 | 3306 | ONLINE || group_replication_applier | 2d623f55-2111-11e8-9cc3-0025905b06da | node1 | 3306 | UNREACHABLE || group_replication_applier | 506759a9-2e83-11e8-b454-525400c33752 | node2 | 3306 | UNREACHABLE |+---------------------------+--------------------------------------+-------------+-------------+--------------+3 rows in set (0.00 sec)# 尝试读写操作## 读操作root@localhost : (none) 10:15:10> use sbtestDatabase changedroot@localhost : sbtest 10:15:52> select * from sbtest1 limit 1;+----+---------+--------------------------------------------------------------------------------------------+-------------------------------------------------------------+| id | k | c | pad |+----+---------+---------------------------------------------------------------------------------------------+-------------------------------------------------------------+| 1 | 2507307 | 68487932199-96439406143-93774651418-41631865787-96406072701-20604855487-25459966574-28203206787-41238978918-19503783441 | 22195207048-70116052123-74140395089-76317954521-98694025897 |+----+---------+-----------------------------------------------------------------------------------------------+-------------------------------------------------------------+1 row in set (0.01 sec)## 写操作root@localhost : sbtest 10:25:43> delete from sbtest1 where id=1; # 写操作被阻塞!!不是报错......[/code]
- 另起一个mysql客户端,登录第三个节点实例中停止组复制插件
- mysqld_safe --defaults-file=/etc/my.cnf &
- # 查看集群成员状态
- root@localhost : (none) 10:15:09> select * from performance_schema.replication_group_members;
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | group_replication_applier | 0a1e8349-2e87-11e8-8c9f-525400bdd1f2 | node3 | 3306 | ONLINE |
- | group_replication_applier | 2d623f55-2111-11e8-9cc3-0025905b06da | node1 | 3306 | UNREACHABLE |
- | group_replication_applier | 506759a9-2e83-11e8-b454-525400c33752 | node2 | 3306 | UNREACHABLE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- 3 rows in set (0.00 sec)
- # 尝试读写操作
- ## 读操作
- root@localhost : (none) 10:15:10> use sbtest
- Database changed
- root@localhost : sbtest 10:15:52> select * from sbtest1 limit 1;
- +----+---------+----------------------------------------------------------------------+-------------------------------------------------------------+
- | id | k | c | pad |
- +----+---------+-----------------------------------------------------------------------+-------------------------------------------------------------+
- | 1 | 2507307 | 68487932199-96439406143-93774651418-41631865787-96406072701-20604855487-25459966574-28203206787-41238978918-19503783441 | 22195207048-70116052123-74140395089-76317954521-98694025897 |
- +----+---------+------------------------------------------------------------------------+-------------------------------------------------------------+
- 1 row in set (0.01 sec)
- ## 写操作
- root@localhost : sbtest 10:25:43> delete from sbtest1 where id=1; # 写操作被阻塞!!不是报错
- ......
- 现在,如果数据量不大,则可以在配置好my.cnf之后直接拉起实例,通过全量binlog复制加入集群(详细步骤可参考3.1.2小节),如果数据量较大,则使用xtrabackup备份方式恢复(详细步骤可参考3.1.3小节)
PS:
- MGR集群多数节点crash之后,剩下的节点可以对外提供读服务,但不可提供写服务,这与MGC、PXC不同(这两种集群多数节点crash之后,读写服务都不能提供)
- MGR集群多数节点crash之后,剩下的节点如果接受到写请求,直接阻塞,而不是报错返回,需要客户端自行断开连接,且断开连接之后,在数据库中对应的事务处于COMMIT状态,不能跟随客户端断开而自行回滚,需要人工干预
- 停止复制插件的方式使得节点脱离集群时,节点当前所有未提交事务会被强制回滚(MGR组复制插件可以stop xxx;start xxx;的方式重启,所以不需要像MGC、PXC那样必须重启实例来重启集群,也就不需要额外的备份操作了)
3.5. 整个集群crash的恢复
- 两种方式
- 使用备份恢复
- 使用crash节点的datadir数据卷进行恢复
3.5.1. 使用备份恢复
- 详细步骤参考3.1.3小节,第一个节点以集群方式启动,其他节点使用备份恢复数据之后直接拉起
3.5.2. 使用crash节点的datadir数据卷进行恢复
- 使用crash节点的datadir数据卷进行恢复需要保证至少有一个crash节点的物理机或kvm可访问(容器环境需要保证至少有一个crash节点对应的node可访问)
- 下面使用sysbench对任意一个节点加压
- [root@localhost ~]# ssh 10.10.30.162 "killall -9 mysqld mysqld_safe 2> /dev/null &";ssh 10.10.30.163 "killall -9 mysqld mysqld_safe &> /dev/null &";
- 同时强杀所有节点的数据库进程(模拟所有节点同时crash)
- rm -rf /data/mysqldata1/{undo,innodb_ts,innodb_log,mydata,binlog,relaylog,binlog,slowlog,tmpdir}/*
- 以非集群方式启动所有节点,并查看所有节点的GTID
- # 查看集群成员状态
- root@localhost : (none) 10:15:09> select * from performance_schema.replication_group_members;
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- | group_replication_applier | 0a1e8349-2e87-11e8-8c9f-525400bdd1f2 | node3 | 3306 | ONLINE |
- | group_replication_applier | 2d623f55-2111-11e8-9cc3-0025905b06da | node1 | 3306 | UNREACHABLE |
- | group_replication_applier | 506759a9-2e83-11e8-b454-525400c33752 | node2 | 3306 | UNREACHABLE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+
- 3 rows in set (0.00 sec)
- # 尝试读写操作
- ## 读操作
- root@localhost : (none) 10:15:10> use sbtest
- Database changed
- root@localhost : sbtest 10:15:52> select * from sbtest1 limit 1;
- +----+---------+--------------------------------------------------------------------------------------------+-------------------------------------------------------------+
- | id | k | c | pad |
- +----+---------+---------------------------------------------------------------------------------------------+-------------------------------------------------------------+
- | 1 | 2507307 | 68487932199-96439406143-93774651418-41631865787-96406072701-20604855487-25459966574-28203206787-41238978918-19503783441 | 22195207048-70116052123-74140395089-76317954521-98694025897 |
- +----+---------+-----------------------------------------------------------------------------------------------+-------------------------------------------------------------+
- 1 row in set (0.01 sec)
- ## 写操作
- root@localhost : sbtest 10:25:43> delete from sbtest1 where id=1; # 写操作被阻塞!!不是报错
- ......
- 从上述信息中,可以看到第一个节点的GTID最大(注意这里主要看集群的UUID对应的GTID,而不是节点的UUID对应的GTID号),事务号为64879507,下面在第一个节点中,拉起组复制集群,并开放对外提供读写服务
- # 存活节点停止组复制插件
- root@localhost : (none) 11:51:15> stop group_replication;
- Query OK, 0 rows affected (1 min 27.08 sec)
- root@localhost : sbtest 11:52:10> set global read_only=1;set global super_read_only=1;
- Query OK, 0 rows affected (0.00 sec)
- Query OK, 0 rows affected (0.00 sec)
- root@localhost : (none) 12:30:20> set global group_replication_bootstrap_group=ON;
- Query OK, 0 rows affected (0.00 sec)
- root@localhost : (none) 12:33:25> start group_replication;
- Query OK, 0 rows affected (2.04 sec)
- root@localhost : (none) 12:33:29> set global group_replication_bootstrap_group=ON;
- Query OK, 0 rows affected (0.00 sec)
- root@localhost : sbtest 12:28:31> set global read_only=0;set global super_read_only=0;
- Query OK, 0 rows affected (0.00 sec)
- Query OK, 0 rows affected (0.00 sec)
写在最后,小编已经把本文完整版与波老师上一篇《MariaDB Galera Cluster(MGC/PXC)重要参数、状态解读大全》两本电子书整理到一起,有兴趣的同学可以扫下方二维码联系助教获取
扫码添加助教
END
扫码加入MySQL技能Q群 (群号:529671799)
戳“阅读原文”了解MGR佳构课
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |
1、本网站属于个人的非赢利性网站,转载的文章遵循原作者的版权声明,如果原文没有版权声明,按照目前互联网开放的原则,我们将在不通知作者的情况下,转载文章;如果原文明确注明“禁止转载”,我们一定不会转载。如果我们转载的文章不符合作者的版权声明或者作者不想让我们转载您的文章的话,请您发送邮箱:Cdnjson@163.com提供相关证明,我们将积极配合您!
2、本网站转载文章仅为传播更多信息之目的,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证信息的正确性和完整性,且不对因信息的不正确或遗漏导致的任何损失或损害承担责任。
3、任何透过本网站网页而链接及得到的资讯、产品及服务,本网站概不负责,亦不负任何法律责任。
4、本网站所刊发、转载的文章,其版权均归原作者所有,如其他媒体、网站或个人从本网下载使用,请在转载有关文章时务必尊重该文章的著作权,保留本网注明的“稿件来源”,并自负版权等法律责任。
|
 代码
1802 人阅读
|
0 人回复
代码
1802 人阅读
|
0 人回复